putting dominator trees to work_
// date: 07 apr 2023// categories: technical
Web performance is unique compared to other types of performance work, largely due to the fact that we need to serve Javascript code to browsers on nearly every request to make sites interactive. Unsurprisingly, the amount of Javascript bytes served is directly correlated with the site’s overall performance.
There is no shortage of content about Javascript dependency management, usually in the context of security issues or versioning, but there’s another problem with gigantic dependency graphs: figuring out how to get rid of unnecessary bytes can be a non-trivial problem.
The need to reduce bytes accumulated through transitive dependencies can’t be
possibly be something that only matters at Facebook’s scale. I imagine that
most medium-or-larger sites end up running into similar problems, either
through pulling in open-source npm dependencies or through having a complex
dependency graph of modules all written in-house.
To get some more anecdata, I checked out LinkedIn’s page load. It’s a
pretty comparable site to Facebook, so I downloaded their homepage Javascript
and one of the larger files I checked had almost 4000 modules defined in it.
I noticed they use Ember, so I typed “ember” into npm search, picked a random
package (in this case, ember-3d-nav) and looked at the dependency
graph.
 behold ember-3d-nav’s (dev) dependency graph: 490 nodes, 1166 edges
behold ember-3d-nav’s (dev) dependency graph: 490 nodes, 1166 edges
Imagine using 10 or more of these packages to build your site – the resulting
dependency graph is difficult to reason about and it can be unclear what the
overall impact of each module is on code size. It would be nice to be able to
answer questions like “how many bytes will I remove if I remove $module from
my application?” and it would be even nicer if we could quickly compute this
for all modules and find the most impactful modules to remove.
dominator trees
Enter dominator trees.
Dominator trees aren’t a new concept. They’re heavily used by compiler writers, for example; they can be used to compute single static assignment forms and other optimizations. For our graphs, we want to leverage another useful property: computing a dominator tree turns any directed graph into a tree. Trees are generally easier to work with than arbitrarily complex directed graphs and the dominator tree has an additional, special property: if you remove a node in the dominator tree, the entire subtree beneath it is no longer reachable from the root.
This fact is more useful than it first appears. In the process of turning the graph into a tree, we end up computing the “exclusive dependencies” of all nodes in the graph at the same time. It’s surprisingly cheap to compute and recompute as you modify the graph, so you can iteratively prune dependencies in real time even on large graphs.

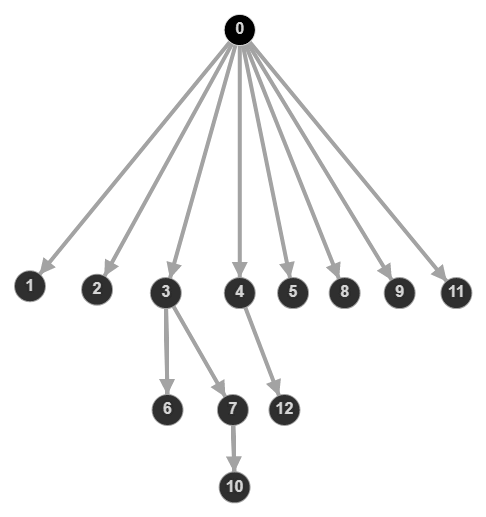 dominator tree transformation
dominator tree transformation
Using the graph above as an example, the dominator tree tells us that removing node 3 makes nodes 6, 7, and 10 unreachable because those are in the subtree rooted at node 3. If you imagine that each node is a Javascript module and the value of the node is its byte size, we can work out the “exclusive” bytes brought in by node 3 by summing up the size of its entire subtree.
The same thing works on your dependency graph. Starting from the root JS modules of a given page or bundle, you can compute the dominators with the Lengauer-Tarjan algorithm, among others. It’s simple enough to implement in an afternoon and even relatively large dependency graphs with over 20,000 nodes are no trouble at all.
how does this help with js size?
The results of this process will give you enough information to construct the tree: the algorithm outputs exactly one parent for each node (except the roots). There are several ways to visualize the subtrees with the largest transitive size, including sunburst charts, a graph with nodes whose radii correspond to the subtree size, or even an expandable table. The dominator tree, unlike the original graph, lends itself to natural, hierarchial visualizations.
To demonstrate this, I wrote a small script that recursively fetches the
dependency tree of an npm package, computes the dominator tree, and renders it
by level. Instead of byte size, it’s counting the number of child packages
in the dominator tree. This gets somewhat difficult to parse on the console and
interactive tools serve this purpose better, but even this simple format leads
to some insights.
$ node dom-tree.js ember-source
↳ ember-source (405 children)
↳ ember-auto-import (83 children)
↳ babel-plugin-htmlbars-inline-precompile (39 children)
↳ string.prototype.matchall (33 children)
↳ line-column (2 children)
↳ magic-string (0 children)
↳ parse-static-imports (0 children)
↳ css-loader (11 children)
↳ postcss (2 children)
↳ postcss-selector-parser (1 child)
↳ icss-utils (0 children)
↳ postcss-modules-extract-imports (0 children)
↳ postcss-modules-local-by-default (0 children)
↳ ...
↳ schema-utils (9 children)
↳ ajv (4 children)
↳ @types/json-schema (0 children)
↳ ajv-keywords (0 children)
↳ ajv-formats (0 children)
↳ fast-deep-equal (0 children)
↳ handlebars (4 children)
↳ minimist (0 children)
↳ neo-async (0 children)
↳ wordwrap (0 children)
↳ uglify-js (0 children)
↳ babel-loader (3 children)
↳ find-cache-dir (2 children)
↳ ...
↳ @babel/preset-env (75 children)
↳ ...
↳ ember-cli-babel (42 children)
↳ fixturify-project (13 children)
↳ bin-links (6 children)
↳ fixturify (4 children)
↳ deepmerge (0 children)
↳ broccoli-babel-transpiler (11 children)
↳ broccoli-persistent-filter (8 children)
↳ hash-for-dep (0 children)
↳ workerpool (0 children)
↳ babel-plugin-module-resolver (3 children)
↳ find-babel-config (0 children)
↳ pkg-up (0 children)
↳ reselect (0 children)
↳ @babel/polyfill (1 child)
↳ core-js (0 children)
↳ amd-name-resolver (1 child)
↳ object-hash (0 children)
↳ ...
↳ broccoli-concat (20 children)
↳ fast-sourcemap-concat (15 children)
↳ memory-streams (8 children)
↳ sourcemap-validator (4 children)
↳ source-map-url (0 children)
↳ find-index (0 children)
↳ lodash.merge (0 children)
↳ lodash.omit (0 children)
↳ lodash.uniq (0 children)
↳ ember-router-generator (12 children)
↳ recast (11 children)
↳ assert (7 children)
↳ ast-types (0 children)
↳ esprima (0 children)
↳ tslib (0 children)
↳ ...
The first few levels of this tree won’t be very interesting; the “exclusive
children” of the root node is the entire graph, after all. However, once you
follow this a level or two deep, you’ll likely find modules that you use for
small bits of functionality that come with a lot of exclusive transitive
dependencies. If you manage to eliminate modules with large transitive subtrees
in the dominator tree, those transitive dependencies will entirely fall out of
the graph. It’s fun to ponder why string.prototype.matchall is exclusively
responsible for bringing in 33 packages.
It’s true that this still isn’t perfect: tree-shaking obviates the need for
some of this, but it’s not magic. Sometimes you still do need to eliminate
bytes from the finished bundles and this approach can often give you a starting
point for substantial byte size wins. It’s most effective for in-house
codebases where you can change anything you want. Unfortunately, you don’t
often control the dependencies of your dependencies in the npm ecosystem, but
it can still show you which packages to consider rewriting yourself if they
pull in more exclusive dependencies than you realized.
is it practical?
In a word: yes. Before we knew about this approach, we had a slower and sometimes-inaccurate way of computing “exclusive dependencies”. One day, after stumbling on this algorithm, we tinkered with it on Facebook’s Javascript dependency graphs and it was enlightening. We immediately found low-hanging fruit and ended up building an entire suite of dependency graph and code size tooling for JS and other codebases with dominator trees as a core feature.
Surprisingly, there are not many results when you search for “dominator tree javascript bytes”. There are some tools that use this for memory graphs to find which nodes are single-handedly causing a lot of other nodes to be retained (it’s an analogous priblem), but none for JS module dependencies and byte size as far as I could find.
I’d love to see this technique translated into a general purpose tool for npm
or, even better, used to find concrete opportunities to remove large exclusive
dependencies in real codebases. I plan to do this at Reddit, but would love to
hear about any other wins people find this way!